

Key Takeaway
RTO (Recovery Time Objective) is the maximum time your business can afford to be offline after an incident. RPO (Recovery Point Objective) is the maximum amount of data you can afford to lose, measured in time. Together, they define how fast you recover and how much you keep. Both should be defined per system based on business impact, compliance requirements, and infrastructure capability.
Every organisation relies on its IT systems, but very few have formally defined what happens when those systems fail. If your servers went down right now, how long could you operate without them? And when they came back online, how much lost data would be acceptable?
These are not hypothetical questions. They are the foundation of every disaster recovery plan, and the answers come down to two metrics: RTO and RPO. Getting them right determines whether a disruption is an inconvenience or a crisis. Getting them wrong – or worse, never defining them at all – leaves your business exposed.
RTO vs RPO: A Visual Timeline
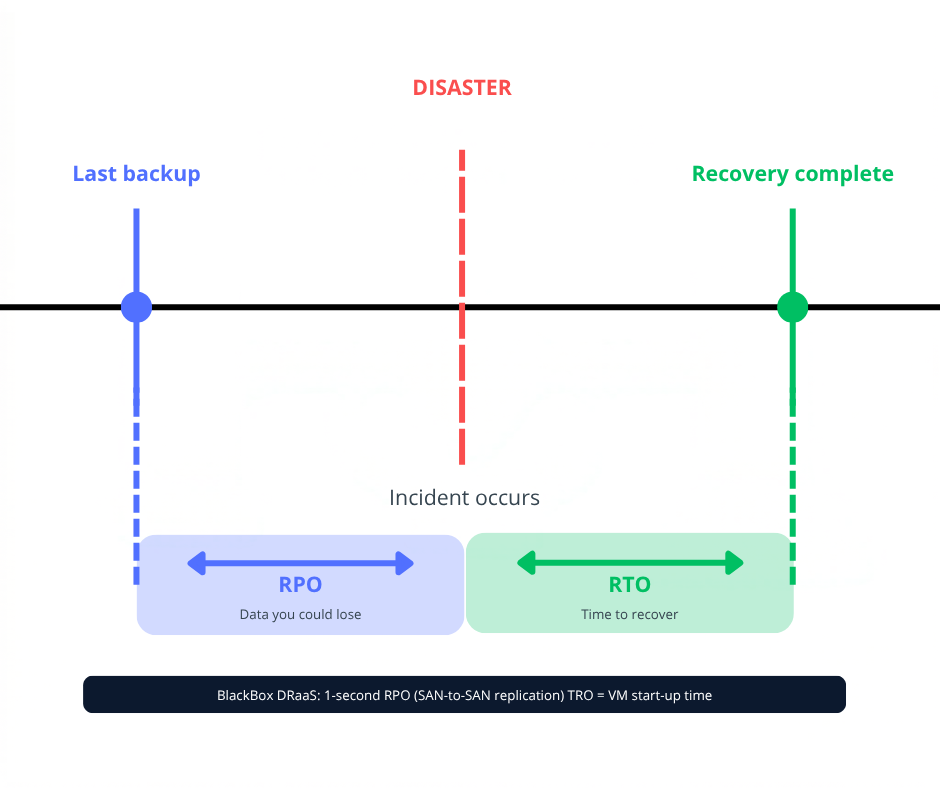
What Is Recovery Time Objective (RTO)?
RTO is the maximum acceptable duration of downtime after a disruption before the impact on your business becomes unacceptable. It answers a single question: how quickly do we need to be back up and running?
An organisation with an RTO of four hours has determined that anything beyond four hours of downtime would cause serious operational, financial, or reputational damage. An organisation with an RTO measured in minutes has a much tighter tolerance – typically because it runs customer-facing systems, financial transactions, or time-sensitive workloads.
RTO is not a single number for your entire business. Different systems carry different levels of criticality. Your email server probably has a more relaxed RTO than your core database or payment platform. Setting RTO means assessing each system individually and understanding the real-world cost of each one being unavailable.
In practice, achieving a tight RTO depends on how your infrastructure is designed. With a properly architected disaster recovery environment, the RTO can be as fast as the time it takes for a virtual machine to start up – meaning recovery happens in minutes, not hours.
What Is Recovery Point Objective (RPO)?
RPO is the maximum acceptable amount of data loss after a disruption, measured as a period of time. It answers the question: if we have to restore from a backup, how much work are we willing to lose?
An RPO of 24 hours means you are prepared to lose up to a full day of data. With a one-hour RPO your backup systems need to capture data at least every 60 minutes. An RPO of near zero means you need continuous replication, because even a small data gap is unacceptable.
RPO is driven by how frequently your data changes and how damaging it would be to recreate or lose that data. A static document archive might tolerate a 24-hour RPO. A transactional database processing customer orders cannot.
RTO vs RPO: Key Differences at a Glance
| RTO | RPO | |
|---|---|---|
| Measures | Downtime duration | Data loss duration |
| Question it answers | How fast must we recover? | How much data can we lose? |
| Unit | Time (minutes/hours) | Time (seconds/minutes/hours) |
| Driven by | Business impact of outage | Data change frequency and value |
| Typical range | Minutes to 24+ hours | 1 second to 24+ hours |
| Infrastructure implication | Failover speed, redundancy | Backup frequency, replication |
How to Calculate RTO: A Worked Example
Calculating RTO starts with understanding the financial and operational impact of downtime for each system. Here is a simplified method:
- Identify the system. For this example: your e-commerce checkout platform.
- Estimate hourly downtime cost. If the platform processes £150,000 in orders per day across 16 active trading hours, one hour of downtime costs roughly £9,375 in lost revenue alone – before you factor in SLA penalties, support costs, and reputational impact.
- Define the pain threshold. If your business can absorb up to £10,000 in combined losses before the disruption becomes a crisis, your RTO is approximately one hour.
- Validate against infrastructure. Can your disaster recovery environment actually restore the checkout platform within one hour? If not, you either need to invest in faster recovery capability or accept a higher risk tolerance.
The same logic applies to RPO. If the checkout platform processes 200 transactions per hour, a four-hour RPO means up to 800 transactions that must be manually reconstructed or are lost entirely. That number defines how frequently your backups or replication must run.
How to Set the Right RTO and RPO Targets for Your Business
There is no universal standard for RTO and RPO. The right targets depend on your specific operations, regulatory environment, and risk tolerance. But there is a clear process for getting there.
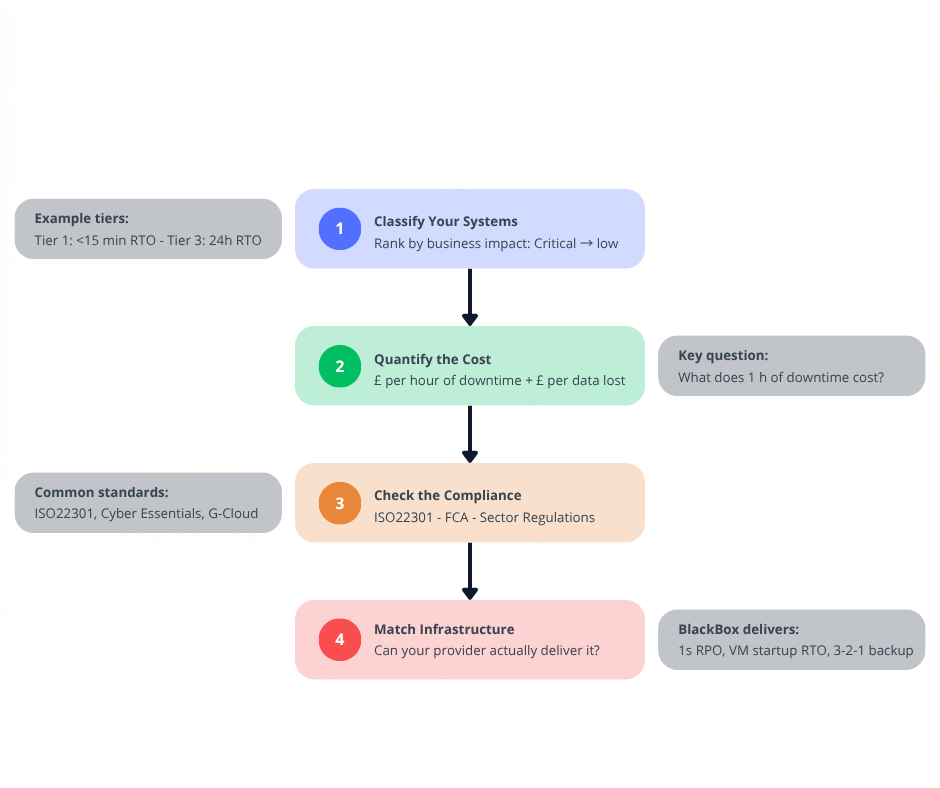
1. Classify Your Systems by Business Impact
Start by listing every system and application your organisation depends on. Then rank them by the impact of their unavailability. Customer-facing platforms, payment systems, and core databases will sit at the top. Internal wikis and archived files will sit at the bottom. Each tier gets its own RTO and RPO targets.
2. Quantify the Cost of Downtime and Data Loss
Put a real figure on what an hour of downtime costs your business. Consider lost revenue, employee productivity, contractual SLA penalties, and reputational damage. Then do the same for data loss. If you process 500 customer transactions per hour, an RPO of four hours means 2,000 transactions that need to be manually reconstructed – or are gone entirely.
3. Factor In Compliance and Regulatory Requirements
Regulated industries often have mandatory recovery requirements. Financial services, healthcare, and public sector organisations may need to demonstrate specific RTO and RPO capabilities to auditors. ISO 22301:2019 (Security and resilience – Business continuity management systems) sets the framework, and regulators like the FCA’s operational resilience requirements add further obligations on top of that.
4. Match Your Infrastructure to Your Targets
This is where the gap most often appears. Businesses set ambitious targets in policy documents but run infrastructure that cannot deliver them.
A four-hour RTO requires automated failover or rapid restore capabilities. A one-hour RPO requires backup systems that run at least every 60 minutes. A near-zero RPO demands continuous replication to a secondary site.
The Relationship Between RTO, RPO, and Backup Frequency
RTO, RPO, and backup frequency are tightly connected but measure different things. Your RPO directly dictates your minimum backup frequency: if your RPO is one hour, your backups must run at least every 60 minutes. If your RPO is near zero, you need continuous replication rather than scheduled backups. Your RTO, meanwhile, determines how your recovery infrastructure must be designed – fast failover for tight RTOs, or slower restore-from-backup for more relaxed ones. Getting these three elements aligned is what turns a disaster recovery policy from a document into a capability.
What Is a Good RTO and RPO?
There is no single “good” RTO or RPO – the right targets depend entirely on the system, the data, and the business impact. However, most organisations find that their critical customer-facing systems need an RTO under one hour and an RPO measured in minutes or seconds, while internal and non-production systems can tolerate much longer windows. The table below provides typical benchmarks by use case.
Typical RTO and RPO Targets by Use Case
| Use Case | Typical RTO | Typical RPO | Why |
|---|---|---|---|
| E-commerce platform | < 1 hour | < 15 mins | Every minute offline is lost revenue; transaction data changes constantly |
| Financial services | < 15 mins | Near-zero | Regulatory requirements and transactional integrity demand continuous protection |
| SaaS application | < 30 mins | < 1 min | End users expect always-on availability; data loss breaks customer trust |
| Internal email | 4–8 hours | 1–4 hours | Disruptive but not business-critical in most organisations |
| Dev / staging | 24+ hours | 24 hours | Can be rebuilt from code; no customer-facing impact |
| Public sector services | < 2 hours | < 1 hour | SLA obligations and public accountability require fast recovery |
Why Most Businesses Get RTO and RPO Wrong
The most common mistake is treating disaster recovery as a document rather than a capability. Organisations write recovery targets into business continuity policies and then never test whether their infrastructure can actually deliver them. The plan exists on paper. The capability does not.
This disconnect is especially common in organisations that rely on public cloud providers where shared responsibility models obscure who is actually accountable for recovery. A hyperscaler will protect their infrastructure. They will not protect your data, your applications, or your ability to be back online within a defined timeframe. That responsibility sits with you – and if your provider cannot demonstrate how they meet your targets, the plan is not real.
“If something goes down at 10 o’clock at night, you need people there to deal with it, and that all adds up. When people compare costs, they don’t always factor that in. With a fully managed service, a lot of that overhead just isn’t there in the same way. It’s not just about having a plan in place – it’s about proving it works under real conditions.” – Matthew Burden, CEO, BlackBox Hosting
Testing Is the Difference Between a Plan and a Capability
The businesses that recover well are the ones that test their recovery process regularly, verify that their RPO and RTO are achievable under real-world conditions, and have a provider that is accountable for the outcome – not just the infrastructure.
How BlackBox Hosting Delivers Against These Targets
At BlackBox, disaster recovery is built into the platform architecture, not bolted on afterwards. The DRaaS platform delivers:
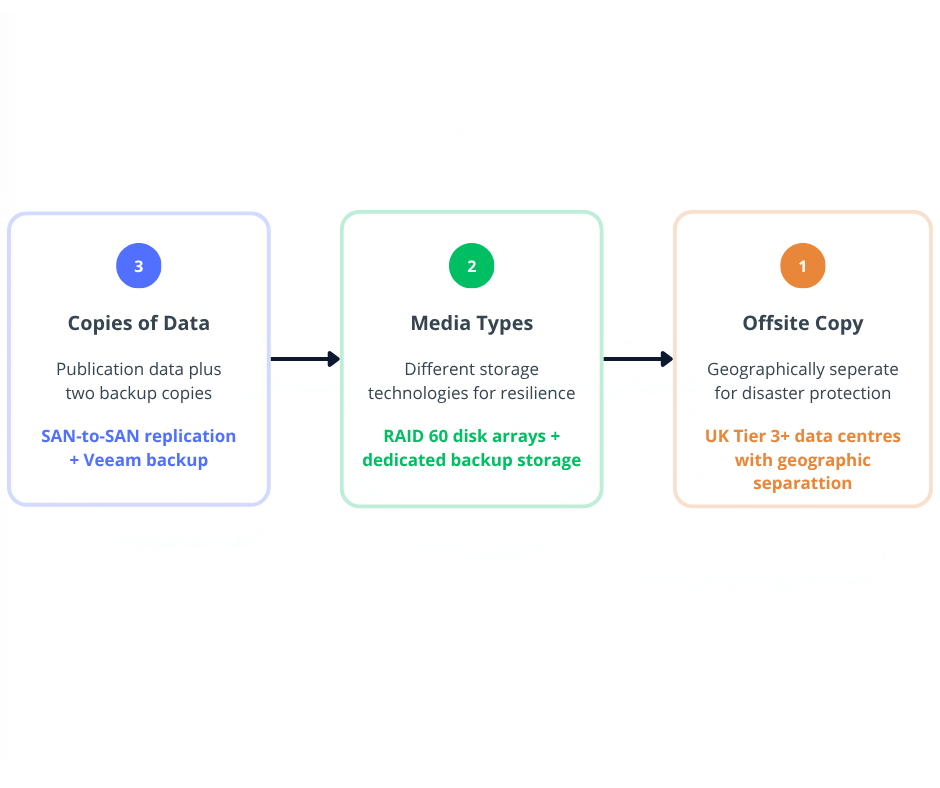
- A 1-second RPO through continuous SAN-to-SAN replication, regardless of the number of servers
- An RTO equal to VM boot time, with automated failover that restores services in minutes
- A 3-2-1 backup strategy powered by Veeam, with immutable backups that protect against ransomware and cryptolocker attacks
- Encryption at rest and in transit across all backup and replication traffic
- Dedicated RAID 60 storage for high-performance, resilient data replication
The 3-2-1 Backup Strategy
For businesses running critical workloads, that level of protection is the difference between continuity and catastrophe. BlackBox holds ISO 22301, ISO 27001, Cyber Essentials Plus, and G-Cloud listing.
FAQs
Common Questions About RTO and RPO
RTO is how quickly you need to recover after an incident; RPO is how much data you can afford to lose. RTO focuses on downtime and RPO focuses on data loss. Both are measured in time and both should be defined for every critical system in your organisation.
It depends on the system. Customer-facing and transactional systems typically need an RTO under one hour and an RPO measured in seconds or minutes. Internal tools and development environments can often tolerate longer recovery windows. The right targets come from assessing the financial and operational cost of downtime and data loss for each system individually.
Start by estimating the hourly cost of downtime for a given system, including lost revenue, productivity, SLA penalties, and reputational impact. Your RTO is the point at which the accumulated cost becomes unacceptable. Then validate that your disaster recovery infrastructure can actually achieve that recovery time.
Achieving zero RTO requires fully redundant, active-active infrastructure with instant failover. Zero RPO requires continuous, real-time data replication. Both are technically possible but significantly increase cost and complexity. Most organisations target near-zero for their most critical systems – for example, a 1-second RPO with SAN-to-SAN replication – and accept longer windows for lower-priority workloads.
At minimum, annually or whenever there is a significant change to your IT environment, business operations, or regulatory requirements. Recovery targets set three years ago may no longer reflect your current data volumes, system dependencies, or compliance obligations.
More Questions About Disaster Recovery
Yes. Cloud hosting does not eliminate the need for defined recovery targets. In shared responsibility models, your provider manages infrastructure resilience but you are responsible for ensuring your data protection and recovery strategy meets your RTO and RPO. Ask your provider exactly what they guarantee – and get it in writing.
Your RPO sets the minimum backup frequency: a one-hour RPO requires backups at least every 60 minutes, while a near-zero RPO demands continuous replication. Your RTO determines how quickly those backups can be restored, which depends on your failover and infrastructure design. Both metrics must be aligned with your actual backup and recovery capabilities.
ISO 22301 (business continuity management) is the primary standard. ISO 27001 (information security) covers the data protection side. For UK public sector work, look for G-Cloud listing and Cyber Essentials Plus. These certifications demonstrate independently audited recovery and security processes. BlackBox holds all of the above.
A 3-2-1 backup strategy – three copies of data, on two different media types, with one offsite – is the baseline. Adding immutability to backups prevents ransomware from encrypting or deleting backup files, which is critical because modern ransomware specifically targets backup repositories. Encryption at rest and in transit adds a further layer of protection.
Need help defining your RTO and RPO targets?
BlackBox delivers a 1-second RPO and VM-startup RTO as standard across its fully managed DRaaS platform – backed by ISO 22301, ISO 27001, and Cyber Essentials Plus.

{kind=link}